
| Sommaire: |

Contrôleur Mémoire :
Explications
Après cette introduction du nForce 4 SLi Intel Edition, il est maintenant temps de voir en détail la principale innovation apportée par rapport à la version AMD : Le contrôleur mémoire intégré. Celui-ci fonctionne sur deux canaux et supporte la DDR-II 400/533 et 667. nVidia a ici volontairement supprimé le support de la DDR-I afin de ne pas rendre le design encore plus complexe, ce qui pourrait potentiellement ralentir la totalité du contrôleur mémoire. Voyons maintenant ce dernier de plus prêt :
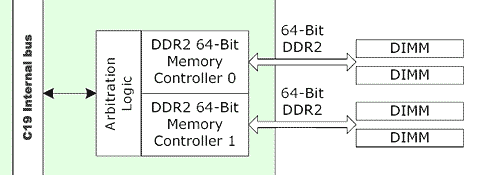
Comme on le voit, il s'agit ici de deux contrôleurs DDR2 64 bits, qui peuvent chacun supporter deux modules de DDR-II. Ces deux contrôleurs sont relier à une logique d'arbitration qui gère les échange avec le bus Interne du nForce 4 SPP. nVidia nous en dit ici plus sur la gestion mémoire du nF4 IE SPP :

Le chipset supporte peut donc fonctionner en mode 64-bit ou 128-bit et supporte jusqu'à 8 banks par chip DDR2., ce qui permet au maximum de supporter 16 Go de mémoire via des modules de 4 Go. Le contrôleur mémoire ne supporte pas les modules ECC ni Registered et peut fonctionner en mode synchrone et pseudo synchrone (nous expliquerons ceci un peu plus tard). Niveau performances, nVidia a doté son contrôleur mémoire de deux technologies visant à améliorer ses performances : le QuickSynch et le Dynamic Adaptive Speculative Preprocessor (DASP) 3.0. Toutefois, avant de rentrer dans les détails techniques de ces deux innovations, voyons d'autres différences architecturales :
- Choix technologiques
Le but de nVidia lors du design du SPP a été de le faire fonctionner en mode DDR-II 667, tout en offrant de bons débits et une latence raisonnable. Pour cela, nVidia à étudier les principaux points ou des problèmes (ou des pertes de performances) pouvait survenir. Le premier point de ce type détecté fût la charge sur les lignes d'adresse. Explication : La mémoire est contrôlée par des lignes d'adresses et des lignes de données. Les premiers se chargent de fournir au module l'adresse mémoire demandée, et les seconds transmettent la donnée qui se trouve dans cette adresse mémoire :
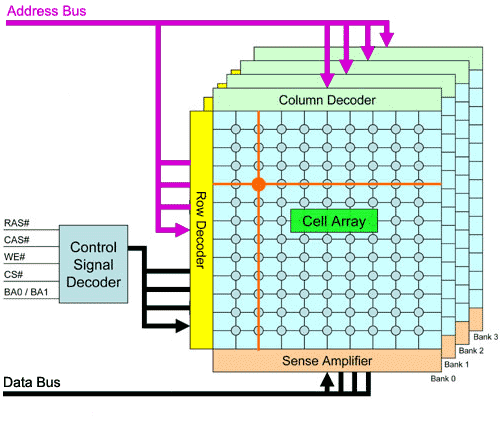
Or, ce bus d'adresse est partagé entre plusieurs modules dans un système classique, ce qui augmente largement la charge (jusqu'a 16 banks) qui transite par ce bus. Selon nVidia, il s'agit la d'une des causes de perte d'efficacité du bus mémoire. Le nForce 4 IE pare donc ce problème d'une façon efficace : Il existe maintenant un bus d'adresse par module de mémoire ! Chacun des 2 contrôleurs 64-bits supporte donc deux bus d'adresse au lieu d'un seul :
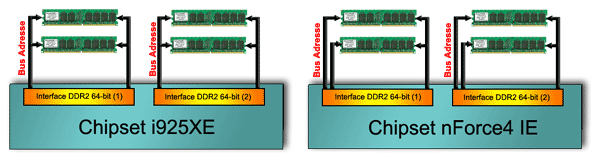
Ceci permet d'atteindre le 1T dans le timing d'adresse, c'est à dire que le l'adresse à lire (ou écrire) est configurée en un cycle d'horloge au lieu de 2 habituellement, comme sur i925XE. Ceci permet d'améliorer la latence en retirant un cycle. Par exemple, dans le cas d'une mémoire configurée en CAS 3 avec le timing d'adresse en 1T, la donnée est rapatriée 4 cycles d'horloge après la requête, au lieu de 5 en mode 2T :
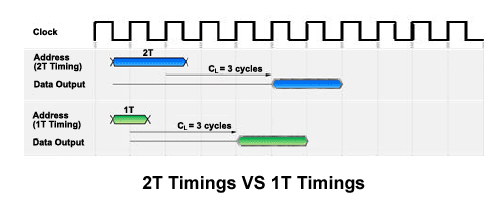
Le fonctionnement par défaut du nForce4 Intel Edition se fera donc en 1T afin de limiter les latences sur les accès à la RAM. Autre choix technique de nVidia, le mode 8T Burst Lenght. La DDR2 supporte des Burst Lenght de 4 et 8. Ce paramètre indique le nombre de paquet renvoyé à chaque requête sur la mémoire. Ainsi, en mode 4T, chaque accès à la ram renverra 4*64 bit = 256 bits en 4 cycles d'horloge. Le mode 8T renverra 8*64 = 512 bits de mémoire en 8 cycles d'horloge. NVIDIA choisit donc ici le mode 4T :
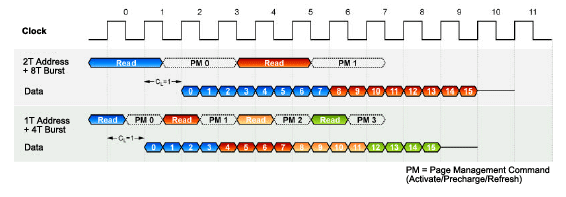
Pourquoi avoir choisi ce mode au lieu du mode 8T, réputé plus efficace ? Nous avons posé la question à nVidia qui n'a pas apporté de réponse claire. Selon nous, nVidia a préféré le mode 4T a cause de sa plus grande stabilité par rapport au mode 8T, pariant que cette légère perte de performance serait largement compensée par le mode d'adressage mémoire 1T. En effet, faire du 333 MHz (DDR-II 667) en mode 1T avec, en plus, un burst 8T est très compliqué et le mode 1T/4T semble plus réaliste. Quoi qu'il en soit, le mode 1T/4T choisit par nVidia devrait se révéler plus performant que le 2T/8T choisi par Intel, c'est ce que nous verrons par la suite.
- DASP 3.0
Le principal tour de force de nVidia pour le C19 est probablement le DASP 3.0, DASP pour Dynamic Adaptive Speculative Preprocessor. Sous ce nom barbare ce cache une technologie qui semble très séduisante sur le papier, mais diablement complexe à mettre en oeuvre. Pour la comprendre, il faut revenir sur quelques points de l'architecture d'un processeur moderne.
Lorsque le core d'exécution à besoin d'une donnée, il va la chercher dans le L1. Si celle-ci ne s'y trouve pas, il tente le L2, sinon, il fait une requête à la mémoire via le chipset et le FSB. Bien entendu, le cache est beaucoup plus rapide que la mémoire et si la donnée ne se trouve pas dans le L2, le fait de la rapatrier de la mémoire entraîne une pénalité importante. Ainsi, le but est de parvenir le plus souvent à trouver la donnée dans le cache (cache hit) et d'éviter le plus possible les échecs (cache miss). Pour ce faire, une technique très utilisée est le prefetcher. En effet, en ce basant sur les instructions qui sont en train d'être exécutée, qui viennent d'être exécutées et qui vont être exécutées dans un futur proche, on peut prédire quelles adresses mémoires vont être utilisées et donc précharger les données dans le cache L2. Si la prédiction s'avère exacte, on peut ainsi s'éviter un cache miss. Voici un schéma de ce fonctionnement :
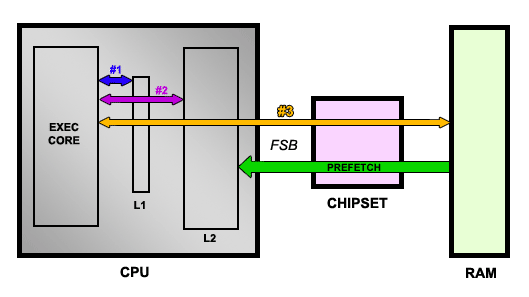
Les données sont donc rapatriées du L1, puis du L2, puis de la RAM. En parallèle, des données spéculées comme étant "utiles" dans un futur proche sont préchargée dans le cache L2 par le CPU. Le prefetcher est une unité extrêmement complexe, qui n'a été ajoutée par Intel qu'avec les Pentium 3 Tualatin. En effet, il faut ici analyser le code à la volée et prédire avec précision les données à précharger. L'exercice est ici encore plus périlleux lorsque le CPU supporte l'Hyperthreading puisque, dans ce cas, le prefetcher doit suivre chaque thread séparément puisque les deux threads accèdent à une partie différence de la mémoire, un vrai casse-tête. Quoi qu'il en soit, l'idée de nVidia avec le DASP est de rajouter un cache, mais dans le chipset cette fois ! Le DASP se charge ainsi, tout comme celui du CPU, de précharger des données en analysant le flux qui transite du CPU à la mémoire. Lorsqu'un cache miss se produit dans le CPU, le core d'exécution va donc tenter d'accéder à la mémoire. Or, si le prefetcher du nForce 4 a déjà préchargé l'information dans son cache interne, celle-ci sera retournée beaucoup plus vite que si un accès à la mémoire avait du être effectuée :
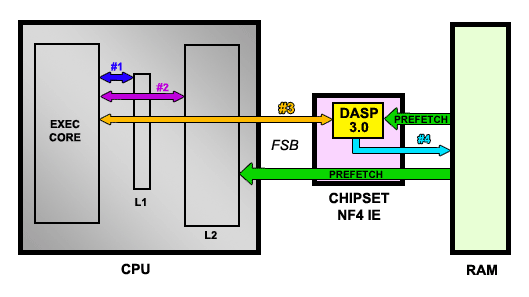
L'idée est séduisante, mais le chipset ne dispose pas de toute la puissance de calcul d'un CPU et, pour être efficace, il faut que le taux de prédiction correcte soit très élevé (> 95%). Si cette technologie va forcement donner d'excellents résultats sur des benchmarks qui effectues toujours la même opération et qui sont donc très simple à prédire, il faudra voir le gain du DASP dans des applications concrètes. Quoi qu'il en soit, le DASP doit ici évaluer un flux de données pouvant provenir de deux threads séparés qu'il doit correctement gérer sans disposer de toutes les ressources du CPU. La prouesse technique est remarquable, sans même qu'on ne parle du cas du CPU Dual-Core avec HT activé ou il y aura 4 threads à gérer ! Mieux, le DASP est capable de modifier son algorithme de prédiction à la volée, complètement ou partiellement, et d'identifier les flux de d'accès à la mémoire provenant du CPU, mais aussi du GPU ou des autres périphériques via les canaux DMA.
- QuickSynch
Le QuickSynch de nVidia a été introduit sur le nForce4 IE afin de parer à un probleme déjà constaté sur le contrôleur mémoire du nForce : Les mauvaises performances en mode désynchronisé. L'explication est simple : Lorsque le bus mémoire et le FSB tournent à la même fréquence, pas de problème. Les données sont transmisses à la suite, sans délai. Par contre, lorsque la mémoire est désynchronisée (par exemple, avec une mémoire qui fontionne plus vite que le FSB), il peut arriver que, afin de garantir la stabilité, le chipset décide de retarder le transfert de la RAM vers le FSB (et vice-versa) en sautant un font du signal, ce qui, au final, rends le mode desynchronisé plus lent que le mode synchrone. Afin de mieux comprendre, nous avons déssiné un schéma clair :
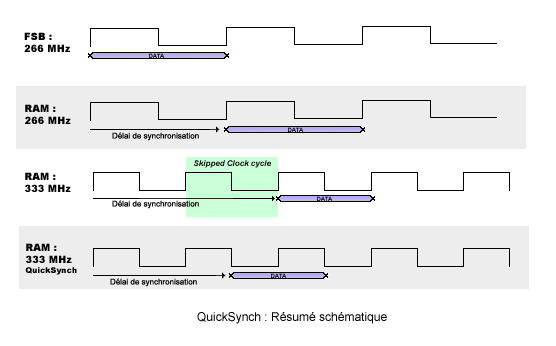
Bien que très simplifié, ce schéma montre bien ici un bus synchrone (266/266), les données se suivent, sans délai. En mode 266/333 (cas du mode FSB1066/DDR-2 667), on voit que, sans mécanisme particulier, un cycle d'horloge est sauté et, au final, la donnée arrive plus tard qu'en mode synchrone : Ce mode est donc plus lent. Avec le QuickSynch, l'enchaînement du flux de donnée peut-être amélioré afin que ce type de problème ne se produise plus, la synchronisation rapide devrait ainsi permettre un mode désynchro efficace.