
| Sommaire: |

Intel Truland :
Xeon MP 64 "Potomac"
Après le serveur et avant le chipset, interessons nous maintenant aux nouveaux Xeons qui accompagnent la plateforme Truland. Connus prédemment sous les noms de code Potomac ("Performance") et Cranford ("Value"), ces processeurs sont donc l'adaptation de la famille Xeon MP au core Prescott (0.09µm). Avant cela, c'est le bon vieux Northwood (0.13 µm) qui servait à cette famille. Destiné à fonctionner en environnement quadri-processeurs, ces Xeon MP ont été lancé en différentes déclinaisons. Les Cranford d'abord, dépourvu de cache L3, sont cadencés à 3.16 GHz et 3.66 GHz. Leurs prix est clairement inférieurs à celui des anciens Xeon MP, merci à l'Opteron. Côté Potomac, le core est identique, mais ceux-ci sont épaulés par un cache L3 de 8 Mo pour les modèles 3.33 GHz et 3.00 GHz, et de 4 Mo pour le modèle 2.8 GHz, comme on peut le voir sur ce tableau :
Core |
Fréquence |
Cache L2 |
Cache L3 |
Prix |
Potomac |
3.33 GHz |
1 MB |
8 MB |
$3692 |
Potomac |
3.00 GHz |
1 MB |
8 MB |
$1980 |
Potomac |
2.80 GHz |
1 MB |
4 MB |
$1177 |
Cranford |
3.66 GHz |
1 MB |
- |
$963 |
Cranford |
3.16 GHz |
1 MB |
- |
$722 |
Avant de parler des nouvelles caractéristiques apportées par ces nouveaux processeurs par rapport aux anciens MP, voyons l'aspect physique d'un d'entre eux :

Physiquement donc, ces Xeons ressemblent traits pour traits aux précédents. A noter qu'ils restent bien plus massif que les Xeon DP actuels, qui ont adoptés un packaging plus petit :

Vu la taille du cache L3, Intel semble avoir choisi de séparer ce cache du reste du die. Bien que, vous le comprendrez, nous n'avons pu nous permettre de décapsuler le CPU, certaines informations du datasheet confirme cette hypothèse, comme on le voit ici

On voit ici clairement un "VCache" qui correspond à l'alimentation électrique du cache L3, ce qui est une quasi-preuve que celui-ci est différencié du die principal. Parlons maintenant des fonctionnalités apportées par ce nouveau Xeon
- Potomac : Nouvelles Features
Le core Prescott permet l'arrivée de tout un tas de nouvelles features, devenues quasiment indispensables dans le milieu serveur. Le 64-bit par le biais de l'EM64T fait bien sûr partir du lot, mais il n'est pas le seul :
Avec 8 CPUs détectés dans le gestionnaire des tâches, on comprend que ces nouveaux Xeon MP supportent bien entendu toujours l'HyperThreading. Pour faire le tour des autres fonctionnalités, il convient de procéder à une étude du CPUID :

On en déduit que :
- NX Bit : CPUID[EAX=0x8000001] / EDX = 0x20100000 - Bit 20 = 1 / Le processeur supporte le NX Bit
- EM64T : CPUID[EAX=0x8000001] / EDX = 0x20100000 - Bit 29 = 1 / Le processeur supporte l'EM64T
- SSE3 : CPUID[EAX=1] / ECX = 0x0000659d - Bit 0 = 1 / Le processeur supporte le SSE3
- EIST : CPUID[EAX=1] / ECX = 0x0000659d - Bit 7 = 1 / Le processeur supporte l'EIST
- TM2 : CPUID[EAX=1] / ECX = 0x0000659d - Bit 8 = 1 / Le processeur supporte le TM2
- VT : CPUID[EAX=1] / ECX = 0x0000659d - Bit 5 = 0 / Le processeur ne supporte pas VT
Rien de bien nouveau concernant le NX Bit ou le SSE3. Par contre, on constate que le processeur supporte l'EIST, mais également TM2, c'est à dire le même mode de régulation très efficace que les Pentium M. A lire la documentation, il s'avère qu'Intel à tout simplement renommé le TM2 en "DBS". Le DBS (Demand Based Switching) est donc l'adaptation aux serveurs de l'EIST, façon Centrino. Autre caractéristique, ces Xeon MP Potomac ne supportent finalement pas VT, la technologie de virtualization d'Intel. Bien que pressenti au départ pour être inclut dans ces Xeon MP, il faudra donc attendre les déclinaisons Dual Core, baptisées PaxVille.
- Core d'execution
Parlons maintenant du core d'exécution. Paradoxalement, il n'y a pas grand chose à dire, à part quelques vérifications. Sur un seul CPU, et avec le cache L3 désactivé par MSR, les performances sont strictement identiques à celle d'un Prescott de fréquence égale. Nous avons toutefois procédé à un test de débit de quelques instructions représentatives :
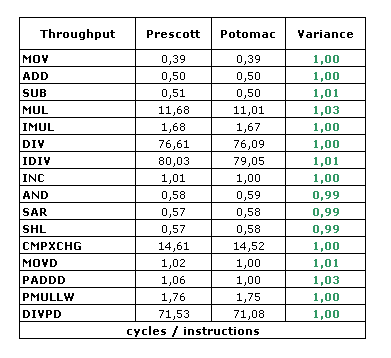
Même core d'execution donc.
- Caches
C'est lorsque nous avons commencé l'étude du cache que nous nous sommes rendu compte d'un point crucial pour ce genre de test : Les benchmarks synthétiques ne sont pas DU TOUT adapté à ce genre de matériel. S'emmêlant les pinceaux entre les processeurs physiques, les processeurs logiques, incapables de détecter la taille du cache L3 et le considérant parfois comme de la RAM, parfois comme inexistant, les tests classiques montrent ici clairement leurs limites. Niveau cache, nous avons eu droit à la totale. Entre RightMark Memory Analyser qui affichait des résultats deux fois inférieurs aux mesures attendues et d'autres softs qui donnait le Xeon MP comme 75% plus performant niveau L2 qu'un Prescott, c'est finalement Sandra qui obtient la palme des erreurs d'analyse, avec des débits de l'ordre de 160 Go/s :
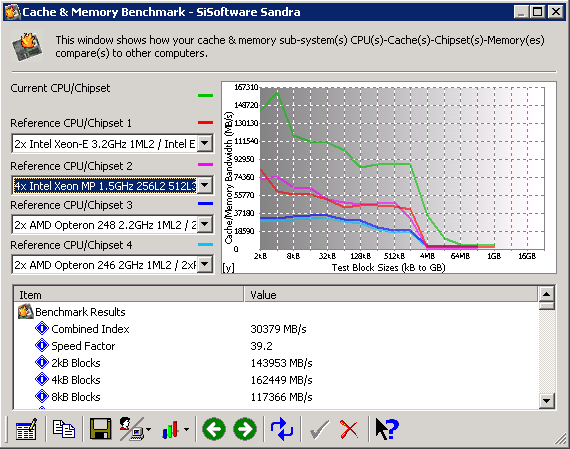
Bref, une vraie galère pour trouver un soft correct qui permette de mesurer précisément les résultats débit et latence de ces caches. Nous avons du nous rabattre sur des solutions maisons, les seules exploitables dans ce genre de cas. Malgré tout, rien ne nous garantis que nous n'avons pas, nous même, fait des erreurs dans le code. Les valeurs retournées semblent toutefois réalistes et crédibles.
Nous avons d'abord tenté de mesurer la latence des caches de la mémoire. Voici les résultats, exprimés en cycles :
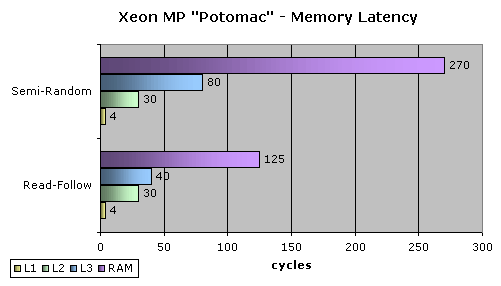
Rien à dire côté L1 et L2 puisque, avec respectivement 4 et 30 cycles, nous sommes typiquement en présence du cache du Prescott. Pour le L3 par contre, les résultats sont plus étranges. "Read-Follow" est un test très simple, avec continuité des adresses testées, c'est typiquement le test synthétique utilisé par les benchmarks. "Semi-Random" est plus proche de ce que les applications effectuent dans la réalité. En accès brut et à la suite, le cache L3 du Potomac est extrêmement performant. Tellement que s'en est troublant. En semi-random, il se comporte normalement, environ 3.3x plus réactif que la RAM. Il semble qu'Intel ait particulièrement optimisé le cache L3 pour des accès gros et continus comme ceux qu'on peut réaliser sur une grosse base de données. Après tout, c'est généralement à ce type d'utilisation que les Xeon MP sont destinés.
Interessant nous maintenant aux débits des caches :
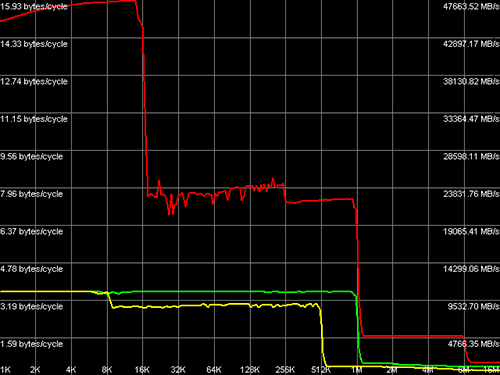
Les résultats sont très étranges. De nouveau rien à dire sur L1 et L2, mais les débits du cache L3 sont lent. Très lent. En effet, là où un Gallatin 2M est capable d'offrir un débit L3 de 10 Go/s, le Xeon Potomac stagne invariablement à 5 Go/s. Pire, le cache L3 ne semble pas être utilisé du tout en écriture. Est-ce du au fait que le cache L3 est externe au cœur d'exécution ? Est-ce une modification destinée à optimiser un certain type de workload ? Difficile d'émettre une hypothèse. Nous avons posé la question à Intel qui devrait nous répondre rapidement.
[EDIT] : Edit avant la sortie du test. Concept intéressant. Avant d'avoir la réponse d'Intel, une théorie est possible pour expliquer les performances du cache : Celui-ci serait en fait connecté, non pas au backside bus du CPU, mais directement au FSB. Très plausible puisque le cache est en faire "externe" au die du Potomac comme nous l'avons vu plus haut. En conséquence, sa vitesse du cache est limitée par celle du FSB, et, en y regardant bien, le cache L3 débite environ 5.3 Go/s, soit exactement le maximum possible par le FSB667. Dans ces circonstances, les débits en écriture sont bridés à la vitesse de la RAM par les write-combine buffers. En contrepartie, un gros gain est effectué sur la cohérence des caches, critique en multi-CPU, et encore plus quand le cache fait 8 Mo...