Pentium 4 0.18 µm : Tests
Notre étude précédente a porté sur le tronc commun de l'architecture NetBurst, et nous allons maintenant regarder les spécificités de deux de ses représentants, les Pentium 4 Willamette et Northwood.
Le Willamette correspond aux
modèles 0 et 1 du Pentium 4.
Le modèle 0 est décliné en deux steppings :
- le stepping B2 (cpuid F07) correspond aux versions Socket 423 PPGA de 1,3 à 1,5GHz.
- le stepping C1 (cpuid F0A) concerne les modèles compris entre 1,3 et 1,8GHz, aux formats PPGA 423 et µPGA 478

Les formats µPGA 478 et PPGA 423 (source
digit-life)
Les caractéristiques du Willamette sont les suivantes :
- Gravure en 0,18µm
- Cache L2 de 256Ko
- Fréquences comprises entre 1,3 et 2GHz
- Packages PPGA 423 broches et µPGA 478 broches, IHS (Integrated Heat Spreader)
Notre étude a porté sur un modèle à 1,5GHz, et lors de certains tests, nous l'avons comparé à un système à base de Pentium !!!-S (Tualatin) à 1,13GHz. Le détail des configurations est ci-dessous :
| Processeur | Pentium !!!-S 1,13GHz | Pentium 4 Willamette 1,5GHz |
| Carte mère | Asus TUSL2-C BIOS 1011 |
Abit TH7-II BIOS TH7_77 beta |
| Mémoire | SDRAM PC133 256Mo | RDRAM PC800 256Mo |
Notre étude de l'architecture NetBurst a montré que celle-ci brillait particulièrement par les débits qu'elle procurait à tous ses niveaux. Regardons donc ce qu'il en est réellement en mesurant les débits mémoires.
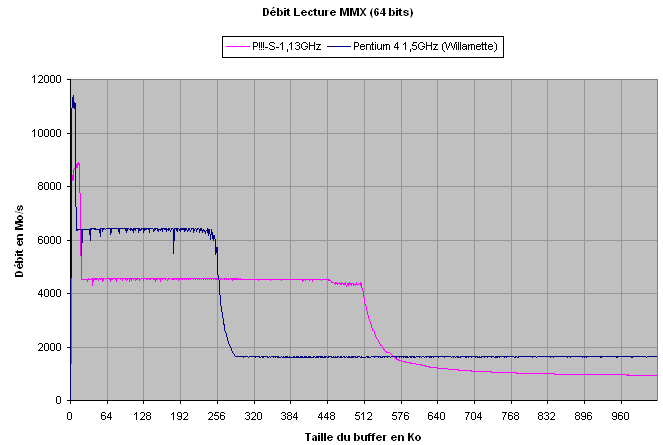
| Pentium !!!-S 1,13GHz | Pentium 4 Willamette 1,5GHz | |
| Débit L1 (pic) (valeur en octets / cycle) |
8920 Mo/s (7,8 o/c) |
11395 Mo/s (7,6 o/c) |
| Débit L2 (moyen) (valeur en octets / cycle) |
4550 Mo/s (4 o/c) |
6200 Mo/s (4,27 o/c) |
| Débit mémoire | 911 Mo/s | 1630 Mo/s |
- La courbe du Pentium 4 met
en évidence les différents niveaux de cache : l'étroit pic du L1 (8Ko)
et les 256Ko de niveau 2, fonctionnant en mode inclusif.
- L'ALU du Pentium 4 nécessite
un cycle pour transférer 64 bits vers un registre MMX, ce qui nous donne
un débit théorique 8 octets (64 bits) par cycle, soit de 8x1500 = 12000
Mo/s pour le Pentium 4 1,5GHz.
Le cache L1 permet une lecture chaque cycle d'horloge, et il offre donc un débit très proche du maximum théorique : 11314Mo/s, ce qui correspond à 7,6 octets par cycle.
- Comme nous l'avons vu précédemment,
le cache L2 permet une lecture tous les deux cycles, soit en théorie
8 octets tous les deux cycles, ou 4 octets par cycle, valeur que nous
retrouvons en pratique.
- Le débit mémoire de notre
système de test équipé de RDRAM est de 1,63Go/s. Nous sommes loin des
3,2Go/s théoriques !
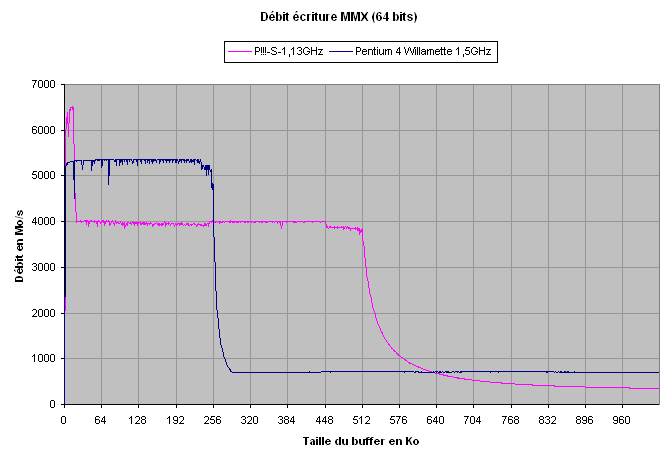
La courbe en écriture du Pentium 4 est caractéristique : le pic du L1 a disparu, mettant ainsi en évidence son mode d'écriture Write-Through, expliqué plus haut. Toute écriture dans le L1 est également effectuée dans le L2, et le débit ainsi obtenu est égal à celui du L2.
A la vue de ces deux courbes, on ne constate rien de bien extraordinaire : le Pentium 4 se comporte pour l'instant comme un Pentium !!! de fréquence plus élevée, et les débits des caches sont du même ordre (mis à part le WT qui apparaît sur la courbe en écriture).
Voyons maintenant les résultats en SSE (transferts 128 bits).
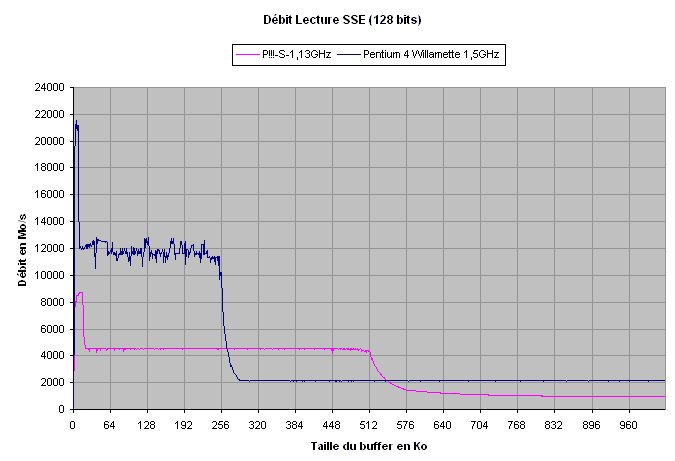
| Pentium !!!-S 1,13GHz | Pentium 4 Willamette 1,5GHz | |
| Débit L1 (pic) (valeur en octets / cycle) |
8741 Mo/s (7,7 o/c) |
21540 Mo/s (14,3 o/c) |
| Débit L2 (moyen) (valeur en octets / cycle) |
4530 Mo/s (4 o/c) |
12200 Mo/s (8,1 o/c) |
| Débit mémoire | 911 Mo/s | 2130 Mo/s |
La courbe parle d'elle-même
: le Pentium 4 double son débit mémoire en SSE. La capacité du Pentium
4 à transférer 128 bits en 1 cycle lui donne une débit maximum théorique
de 16 octets par cycle, soit 24000 Mo/s à 1,5GHz.
La valeur obtenue sur le L1 s'en approche avec un débit de 21540Mo/s.
Quant au L2, il atteint son débit maximum théorique de 16 octets en 2
cycles, soit 8 octets par cycle.
Le débit mémoire a également augmenté pour atteindre 2,13Go/s. Cela peut s'expliquer par les transferts de 128 bits qui nécessitent deux fois moins d'accès à la mémoire que lors de transferts 64 bits (MMX), diminuant ainsi les temps d'accès, et donc le débit global. Cet écart assez important trahit un des défauts majeurs de la RDRAM, à savoir des temps d'accès élevés.
- Etude des latences
Dans ce test nous avons mesuré le temps de réponse des mémoires cache, c'est-à-dire le temps entre la requête de lecture depuis la mémoire jusqu'à l'obtention effective de la donnée. Pour cela, nous avons utilisé un programme dont le principe est de lire des données dans un buffer mémoire à des intervalles réguliers appelés « stride » (pas).
Voyons les résultats obtenus sur le Pentium !!!-S et le Pentium 4.
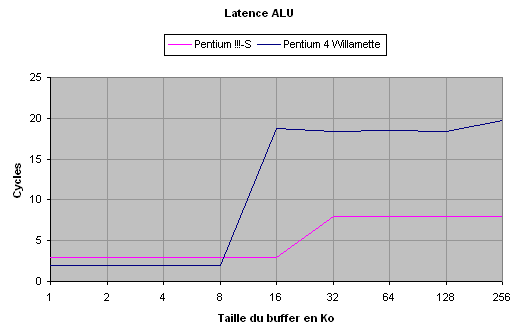
Les valeurs de latence mesurées sur le cache L1 sont conformes à ce qu'Intel annonce : 3 cycles pour le Pentium !!! et 2 cycles pour le Pentium 4.
La situation s'inverse sur le cache L2 : 8 cycles pour le Pentium !!!, et pas moins de 18 cycles pour le Pentium 4. Pourquoi Intel annonce-t-il une valeur de 7 cycles ? En réalité, il faut chercher les raisons de cette latence élevée dans la taille des lignes de cache.
En effet, l'accès au cache L2 a lieu en cas d'échec en lecture dans le L1. Dès lors, une ligne de cache est extraite du L2, puis copiée vers dans le L1 par le bus d'échange large de 256 bits, soit 32 octets. Le cache L1 du Pentium !!!-S possède des lignes de 32 octets, ce qui ne nécessite qu'un seul accès au cache L2. Celui du Pentium 4 en revanche a des lignes de 64 octets, ce qui nécessite alors deux transferts par le bus de 32 octets, soit deux accès au cache L2. La latence ainsi mesurée correspond en réalité à deux accès au cache L2.
Les 18 cycles se décomposent donc en 2 cycles d'accès au L1 et 16 cycles pour accéder deux fois au cache L2, dont la latence est donc de 8 cycles. Nous retrouvons ainsi une valeur proche de celle annoncée par Intel.
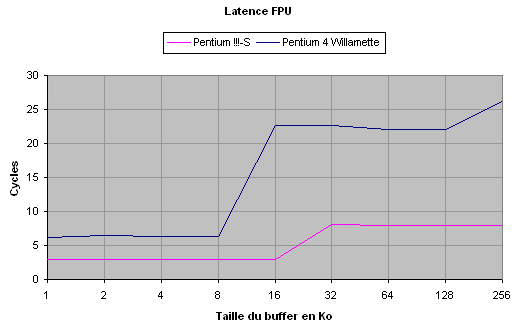
Le mécanisme de spéculation du cache L1 ne s'applique pas pour les accès
depuis la FPU, et la latence passe ainsi à 6
cycles.
La latence du cache L2 est de 22 cycles, qui se décomposent en 6 cyles
d'accès au L1 et 16 cycles pour deux accès au L2. La véritable latence
du L2 est donc de 8 cycles depuis la FPU.
Remarquons qu'en ce qui concerne le Pentium !!!, l'accès depuis la FPU ne modifie pas les temps de latence.